Wordle Solving with Deep Reinforcement Learning
Jan 2022
TL;DR
You can test out the Deep RL agent yourself here. (This is hosted on free tier so please be patient if it needs up to a minute to spin up).
The current best model I trained played a total of around 20M games before it was decently good, and now has ~99% win rate, averaging less than 4 guesses per game. It’s still improving as I write this.
If you don’t want to read all this nonsense, the approach that worked for me was A2C (Advantage Actor Critic), a policy gradient method. I used a staged training approach where I progressively trained the network to solve harder and harder problems (through increasing vocabulary size) and warm-started each time it started a more difficult problem. I also designed a neural net where instead of learning the full space of ~13k possible discrete actions, the model only needed to learn 130 outputs.
Because of letter scarcity, the model was pretty bad at some words like PIZZA.
To help with this, I set up a “recent losses” FIFO queue with fixed capacity, and whenever the model lost in training, pushed the target word on to it.
Whenever the environment reset, I set a 10% probability of drawing a word from the recent losses queue instead of randomly from the vocabulary, enabling the model to get more practice on the words it was struggling with.
Words it was struggling with would end up in the queue more often, giving it even more chances to practice.
Once it figured it out and was solving consistently, they would slowly be replaced by new challenging words.
This approach helped halve the rate at which the model lost games, going from 2% to 1%.
It now handles PIZZA quite well.
I also tried Deep-Q learning (DQN), but it didn’t seem to work for me on the full sized problem. I started to experiment with Soft-Actor Critic (SAC) before I realized A2C with bootstrapped training was going to work on the full problem size.
Like a lot of people, I’ve been playing the daily Wordle challenges since I found out about them. Even my mom’s been sharing her daily scores in my family’s group chat.
How to play Wordle
Just in case you haven’t played Wordle, it’s a game where you have to guess a 5 letter word within 6 tries. After each guess, the game will tell you which letters are in the correct spot, which are in the wrong spot, and which don’t appear in the word at all.

One of the big challenges is that your guesses must be a valid word; i.e. you can’t just enter characters that you want to try out. It’s quite a challenging game the first few times you play! Anecdotally though, most people are able to figure out the words within 3-5 guesses.
I’d just finished replaying Advent of Code so I could learn some golang, and was looking for another excuse to play with go.
Existing solutions
I thought maybe a Wordle solver would be the way to go. I was curious about what other people have been trying, and one of the first hits to come up was this post on a minimax method. The approach described there is to choose the word that minimzes the worst case scenario. The author tested it’s worst-case performance as 5 guesses, which is extremely good for such a simple heuristic! However, in my experiments with it, it often took more guesses than I took, and I’m quite the novice.
Reinforcement Learning
After scratching my golang itch and reimplementing the minimax in go, I figured the next thing I should try to do is incorporate some sort of information on how frequent certain words are. In the Minimax problem there are ~13k possible words to guess, and the best one in a given situation probably maximizes some expectation, which is exactly what reinforcement learning is trying to do.
In the Reinforcement Learning setting, you are an agent with some notion of state, and are able to take some action. The environment will update the state based on the action you take. The goal of the agent is to learn the policy that, given a current state, chooses the action that maximizes the agent’s total expected rewards.
For small problems you can use value or policy iteration techniques to get to the optimal policy. Unfortunately I wasn’t able to come up with a tractable problem. One way to represent the state is, for each letter, to track whether it’s been attempted, and if it has, which spaces it’s still possible for (i.e. yes, maybe, no for each of the 5 spots). You could store this in a binary vector of size 26 + 3526, width 416. The full state space has a mere 2^26 * 3^5^26 possibilities.
Most of these states are unreachable though. A smaller bound on the problem size is that there are 13k actions you could take at each turn. After each of these steps, the game can respond with one of 3^5 combinations of No’s, Maybe’s, and Yes’s. So you could think of this as (13k * 3^5)^6 possible sequences, approx. 10^38.
Picture of Wordle Debugging state, target word was “WHEEL”, it won on the 6th try.
So ignoring for now the fact that that’s still an astronimically large number, one approach to RL is to ask, given my current state, what’s the action that maximizes my expected reward? You could store this data in a 2D array, a “Q-table”, indexed by the current state, and the set of available discrete actions, with the values as the expected reward for taking an action in a given state. Once the table is filled in, you just choose the action with the largest expected value given your current state, play the word, and then see what state you end up in next. This is the value iteration approach.
Deep Learning
Enter model-based approaches, where you use some parameterized function to approximate the Q-table , say a linear combination of the state vector. Deep Q learning is just using a neural network as this function approximator. More recently however, Policy Gradient methods seem to have had more success than Deep Q learning. I tried both Deep Q learning and Advantage Actor Critic (A2C) methods because they had example implementations in Pytorch Lightning, which made it easy to get started. I highly recommend the papers and this youtube series of lectures as well as they’re very digestible.
The idea behind policy gradients is really damn cool. Basically if you have a discrete action space (like we do in the case of Wordle), gradient descent doesn’t work well because the Agent’s approach is to choose the action that maximizes some expectation, and for lack of better words, maximums make gradients sad. The trick with policy gradients is to make the Agent choose actions probabilistically, and now based on your loss function, you can nudge the Agent to make that action more or less probable.
State and Action representation
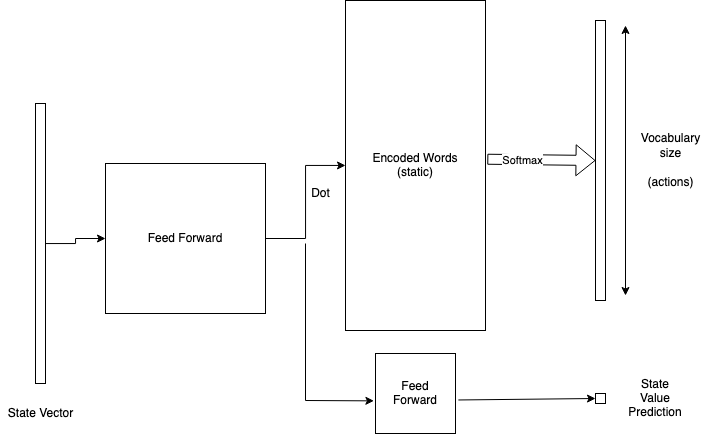
Wordle-Net, simply feed-forward and dot with vocabulary encodings.
The state vector I used was an integer vector of size 417, one for the number of remaining turns, and the rest to represent the state I described above.
A naive approach to the approximator would be to take the 13k actions as the output layer of say an MLP (multilayer perceptron), and have your agent learn that action space. However for Wordle, there’s a lot of information in the characters that make up the words, and I didn’t want that to go to waste.
The neural network I designed for both DQN and A2C takes this vector as input, feeds it through an MLP with some hidden layers to an output layer of size 130. Because the output word has a fixed size (5) I one-hot encoded every word in the vocabulary to get a 130-wide one-hot representation for the word (26*5). Taking the dot-product of the MLP output layer and this matrix of one-hot encoded words gets you a single value for each of the 13k possible actions.
This is essentially constraining the value of each word, given an input state, to be the sum of it’s letters. It’s not clear if this is too restrictive, and it might be a good idea to learn embeddings for the encoded words first, but it’s given decent results so far. For Deep Q learning, we use this as the predicted Q-value of taking this action in the given state. For policy gradients, we pass this through a softmax layer to get probabilities.
Wordle Environment and Training
All that’s missing now is the Wordle environment and to train these networks.
I broke the problem up into tiny, small, medium, and large vocabularies to test that things were working correctly. I highly recommend you do this if you’re starting on a new project.
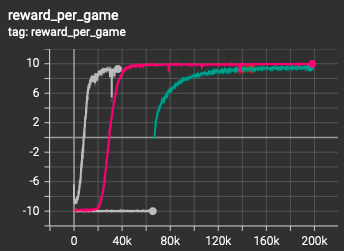
Average reward per game during training. Winning a game is worth 10, losing a game is -10.
The first problem/testing ground had a vocabulary of 100 words, and for the environment to always choose the same word as output, so basically no randomness. If your model couldn’t figure this out, there was a serious problem somewhere.
The next step up was the same 100 words, but randomly choosing between 2 outputs. I caught a few bugs here around network setup and also related to mutable states (I since refactored away mutable states as much as possible, but this is why you don’t make things mutable)!
Once I was fairly confident that most of the big bugs were out, it’s time to start training on real problems. The first small problem was the same 100 word vocabulary, but now the environemtn was randomizing between all of the words.
This took the agent around 500k - 700k games to learn to play well, with around a 96% win rate, averaging 2.5 guesses per game. At this point I didn’t really need it to do better because it wasn’t working on the full game.
The medium problem had a vocabulary size of 1000, with all words as possible targets. The A2C agent was able to learn this game from scratch after playing ~5M games. It had a win rate over 99% and 3.5 turns per game.
The full sized problem has 13k valid words, however I learned recently that only 2315 are eligible as targets. This makes the problem still quite difficult but much easier than 13k vocab with 13k possible targets! I struggled to get this one going from scratch, with millions of games played and no signs of learning.
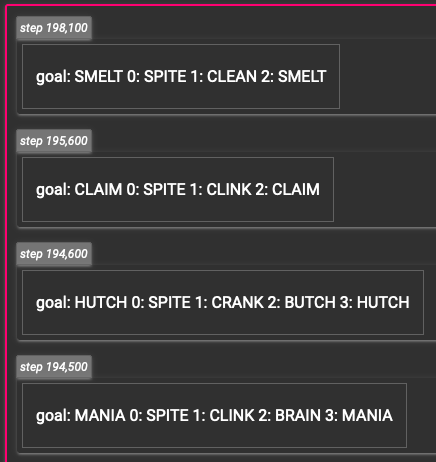
Sampled training games.
What worked was to warm-start from the model that trained on the 1000-word training set. This had fantastic results. With network architecture and state designed the way they were, the new model was able to use what it learned from the smaller vocab set and put it to use immediately on the full set. The model is still learning but it’s at around a 98% win rate, averaging ~4.13 guesses per turn, however the model is still improving. I don’t quite think this is human-level performance yet, my gut says that’s somewhere in the low to mid 3’s.
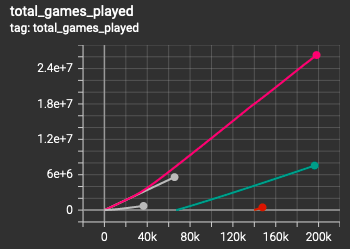
Games played during the staged/bootstrapped training process.
Results (so far)
The model so far is doing alright, though I think it has a ways to go before getting to human level. It doesn’t seem like it will be particularly hard to get this to work, but I’m a bit annoyed at how many games it takes to learn! Another side note is that it’s pretty great how good a heuristic can perform, but that isn’t why we have side projects is it -.-;;;;
Looking at some sampled output from the model, it does seem to have settled into a strategy of selecting STARE and then some version of CLINK or CLINE or CLEAN given the result of the input.
This seems to match up pretty well with the “Wheel of Fortune” approach of going RSTLNE.
I encourage you to try, but given this is hosted on Heroku free, you may need to give it a minute as the instance spins up.
Currently it has a “Goal” mode where you give it a word and it’ll play 6 turns, and a “Suggestor” mode that’ll give you a suggestion if you tell it what you’ve tried and the wordle responses so far.
Games played during the staged/bootstrapped training process.
What will happen to this Wordle-bot now? I may give it twitter account to play the daily wordle, or else hae it calculate some historical stats on past games.
A few things I want to try in terms of improvement:
-
It’s still improving as I’m writing this up, so I’ll continue to let these go and see if they can get over the hump. For the medium model, it hovered around 1% failure rate before hitting policy leaps that let it jump out of the local minima.
-
I am currently trying something where I keep a “recent failures” queue, and 10% of games are sampled from this queue. The idea is to give it more practice on the things that it needs work on. TBD if this works out.
-
One thing that probably helped the model is the rich state that I gave it, however the problem with it is that I actually took some shortcuts and didn’t handle double letters that well. For example, if the goal word is
LATERand you the Agent triesTATER, Wordle would tell you that the middleTis correct, and the first one is not. This lets you rule out all the otherT’s in the word, however the state update that I defined ignored this subtlety and only sets theTin the first position of the word as a no. -
There’s also possibilities to try a richer word encoding instead of the one-hot that I started with. Maybe having each letter in each position map to an embedding would give better results.
-
Finally, I’ve tried to help the model learn as much as I can with the state and the word emcodings, but given the success of DeepRL with very very little input processing, I’m wondering how it would do with less rich state. For example, you could imagine just passing in words and the mask outcomes from Wordle in a sequence and feeding it through some recurrent network or other transformer. I may need a bigger GPU for that though, I’m not sure.